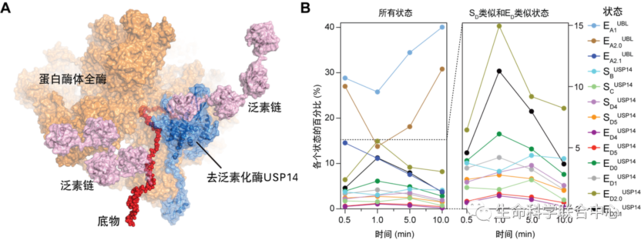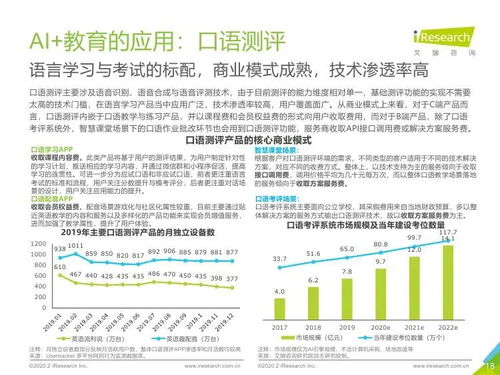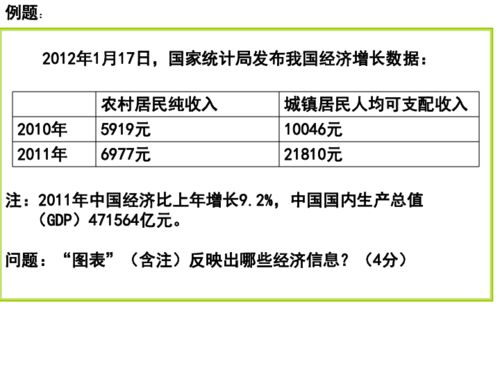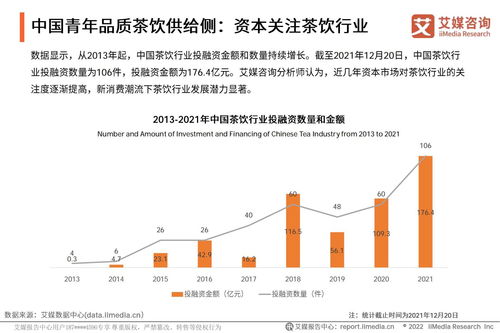
在当今人工智能与医学交叉领域,预训练模型(如BERT)与知识图谱的融合已成为推动医学研究和试验发展的重要驱动力。这种结合不仅增强了模型对复杂医学知识的理解能力,还为疾病诊断、药物发现和临床试验优化提供了新思路。
预训练模型通过在大规模文本数据上的学习,能够捕捉丰富的语言表示,而知识图谱则整合了结构化的医学知识,如疾病关系、药物相互作用和基因通路。将两者结合,可以弥补预训练模型在专业医学知识上的不足,提升模型在医学任务中的准确性和可解释性。例如,在疾病预测中,模型可以利用知识图谱中的实体关系来推理潜在风险,而BERT则帮助解析非结构化临床文本。
在医学研究方面,这种融合技术已应用于多个领域。在基因组学中,研究人员结合预训练模型和知识图谱分析基因表达数据,识别与疾病相关的生物标记物。在药物研发中,模型可以整合知识图谱中的药物-靶点信息,加速新药候选物的筛选过程。在临床试验设计中,通过融合患者数据和知识图谱,模型能更精准地匹配受试者,提高试验效率。
挑战依然存在。医学知识图谱的构建需要大量高质量数据,且预训练模型可能面临数据隐私和偏差问题。未来研究方向包括开发更高效的融合算法,如引入图神经网络(GNN)增强知识嵌入,以及探索联邦学习以保护患者隐私。
BERT与知识图谱的结合为医学研究和试验发展开辟了新路径。随着技术的不断成熟,这一融合有望在精准医疗和个性化治疗中发挥更大作用,最终造福人类健康。